

The theory behind Memory Management - Concepts
A deep dive into Memory Management and how it is implemented in different programming languages



In the past few days I've been researching memory management and how is it implemented in different programming languages. I thought about sharing some of the most important insights I learned in the process. In this part I will focus on the main concepts that revolve around this topic and in next parts I will focus on different programming languages (Java - Python - Go - Rust) philosophies towards managing their memories.
What's Memory Management?
Memory management is the process of controlling and coordinating computer memory, assigning portions called blocks to various running programs to optimise overall system performance. Memory management resides in hardware, in the operating system, and in applications. We will focus more on how applications (Programming Languages) interacts with the OS to manage its memory.
As far as application memory management goes, it only cares about two main task, known as allocation and deallocation/recycling.
When an application runs on a target OS, it needs access to the RAM(Random-access memory) for many things, we will focus here on only two:
- Write the data and variables being used while the program is executed
- Read these data when are needed
In order to do this, the application uses two regions of memory: The Stack and The Heap.
Stack
- Variables created on the stack will go out of scope and are automatically deallocated.
- Much faster to allocate in comparison to variables on the heap.
- Implemented with an actual stack data structure.
- Stores local data, return addresses, used for parameter passing.
- Can have a stack overflow when too much of the stack is used (mostly from infinite or too deep recursion, very large allocations).
- Data created on the stack can be used without pointers.
- You would use the stack if you know exactly how much data you need to allocate before compile time and it is not too big.
- Usually has a maximum size already determined when your program starts.
- Memory management of the stack is simple and straightforward and is done by the OS.
Heap
- Variables on the heap must be destroyed by the program and never fall out of scope.
- Slower to allocate in comparison to variables on the stack.
- Used on demand to allocate a block of data for use by the program.
- Can have fragmentation when there are a lot of allocations and deallocations.
- Can have allocation failures if too big of a buffer is requested to be allocated.
- You would use the heap if you don't know exactly how much data you will need at run time or if you need to allocate a lot of data.
- Responsible for memory leaks.
The important takeaways from here are:
- Memory management of the stack is cheap and taken care of by the OS.
- The heap on the other hand needs to be managed by the application itself. Some applications decided to entrust the developer with this task and only provided them with the tools necessary to allocate/free heap memory while other applications implemented their own automatic memory management strategies.
Manual memory management
Some languages like C and C++ provide (malloc and free) methods to allocated and free the memory (In addition to other methods). The developer will be responsible to allocate and free their data from the heap.
Automatic Memory Management
AMM is a technique in which an operating system or application automatically manages the allocation and deallocation of memory. This means that a programmer does not have to write code to perform memory management tasks when developing an application. Automatic memory management can eliminate common problems such as forgetting to free memory allocated to an object and causing a memory leak, or attempting to access memory for an object that has already been freed.
Garbage Collector (GC)
A Garbage Collector (GC) is a task that deletes occupied memory allocated by a program. GCs look for memory that is no longer referenced anywhere in the program. When found, data occupying this memory space is deleted and the region is reclaimed for future use.
There are two popular approaches that languages use to implement GC: Reference Counting and Tracing.
Tracing (Mark and Sweep)
Its generally a two-phase algorithm that first marks objects that are still being referenced as “alive” and in the next phase frees the memory of objects that are not alive. When a GC uses tracing, it defines root objects or data and checks their reference chains. If an object is referrable directly or indirectly from a root object, the GC keeps it alive. If an object doesn't appear anywhere on the reference chain, it is deleted.
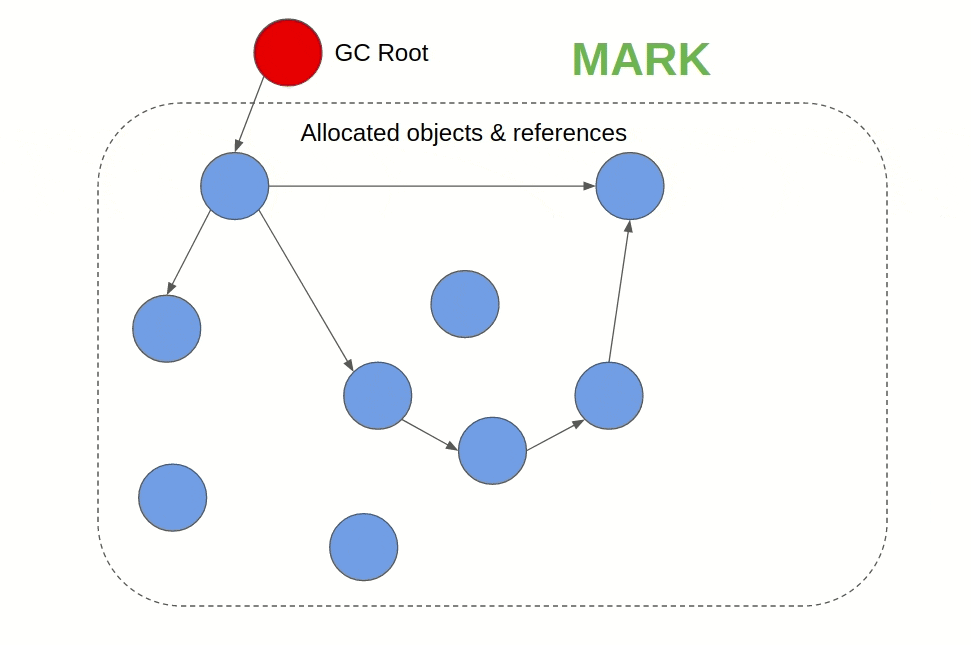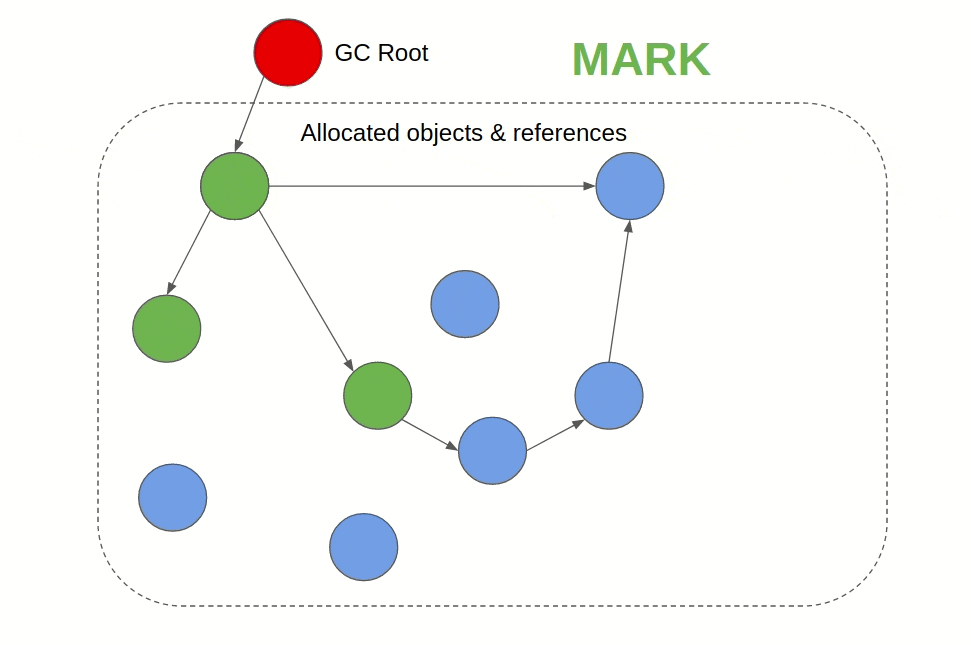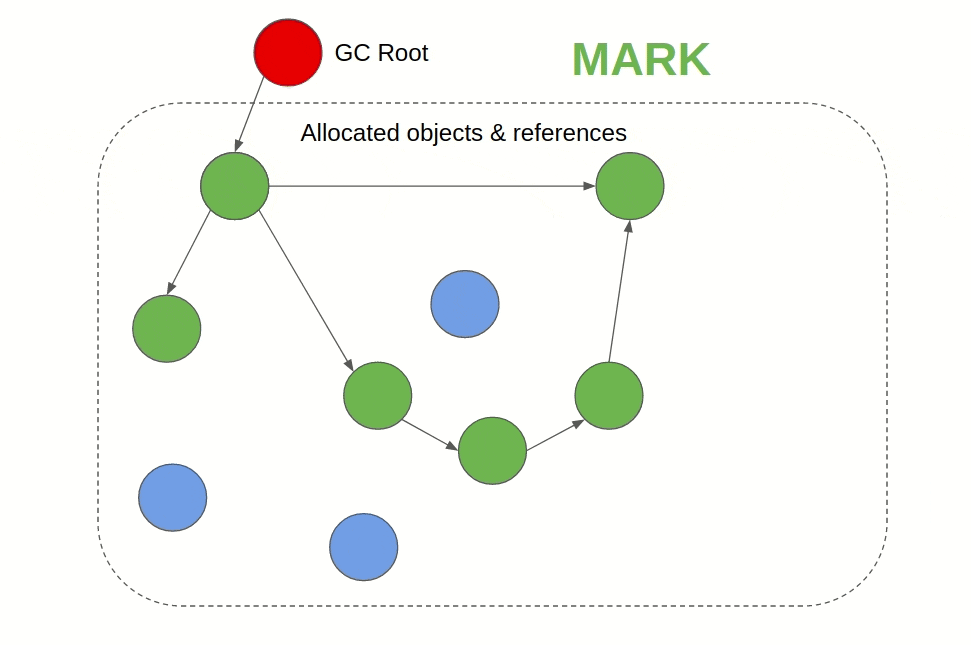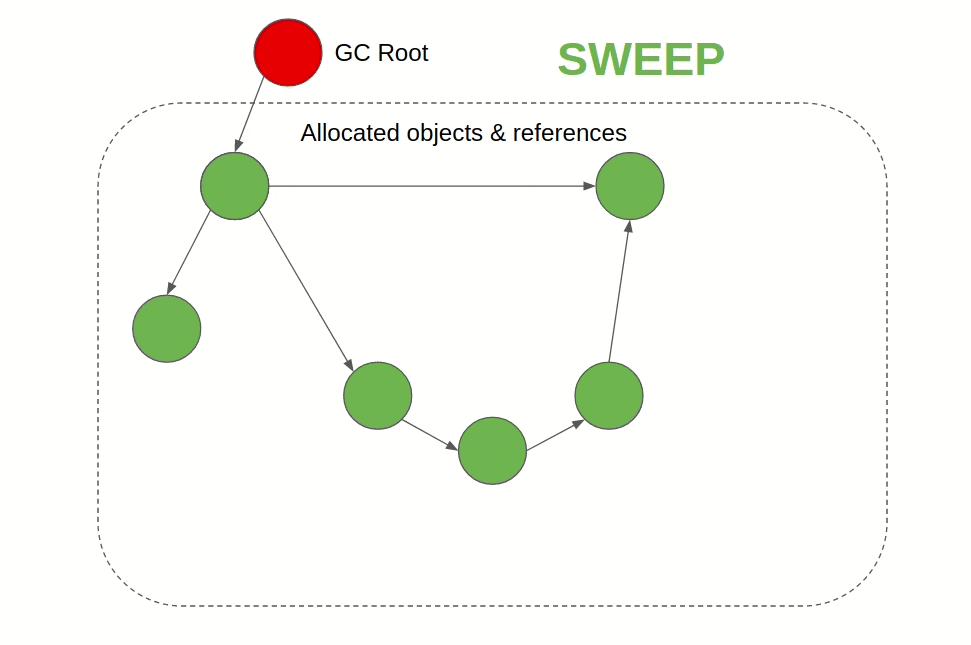
Reference Counting
Reference counting in the context of garbage collection is when each object or data maintains a counter. This counter represents the number of other objects or pieces of data that maintain a reference to it. For example, for objects A, B, and C if object B contains a reference to A and object C contains a reference to A, the reference count of A is two and garbage collection is done when the counter becomes zero. It’s not very preferred as it cannot handle cyclic references.
Cyclic References
It is the condition when 2 objects keep a reference to each other and are retained, it creates a retain cycle since both objects try to retain each other, making it impossible to release even though there are no external references. At this point, you have a memory leak. It takes some workarounds to prevent Cyclic References while using Reference Counting.
Stop-The-World Mechanism
Stop-the-world is a mechanism that languages often use to suspend the execution of a program for the GC until all objects in the heap are processed and identified wether they should be marked as alive or not.
Generational Garbage Collection
It has been known since 1984 that most allocations “die young” i.e. become garbage very soon after being allocated. So in addition to the reference counting or tracing strategies, Some languages also uses a strategy called a generational garbage collector. The garbage collector is keeping track of all objects in memory. A new object starts its life in the first generation of the garbage collector. If the language executes a garbage collection process on a generation and an object survives, it moves up into a second, older generation. And so on for a defined number of generations. The younger generations will have minor GC processes running over smaller intervals when needed while the older ones will have major GC processes running over a longer intervals when needed. This allows the languages to be able to run two different garbage collectors on different intervals to decrease the amount of the stop-the-world time needed.
Automatic Reference Counting
It’s similar to Reference counting GC but during compile time, it inserts messages like retain and release which increase and decrease the reference count at runtime, marking for deallocation of objects when the number of references to them reaches zero. Unlike GC, it isn’t a background process and it removes the objects asynchronously at runtime. The main difference between ARC and RC GC is in the stop-the-world mechanism. In ARC, you don't need a stop-the-world mechanism to deallocate objects. It also cannot handle cyclic references and relies on the developer to handle that by using certain keywords depends on the implementation.
Memory Fragmentation
Memory fragmentation is when most of your memory is allocated in a large number of non-contiguous blocks, or chunks - leaving a good percentage of your total memory unallocated, but unusable for most typical scenarios. Consider the request of a contiguous memory block from our program using a function malloc(size) and releasing that memory back using a function free(pointer) in a sequential way from p1 to p4.
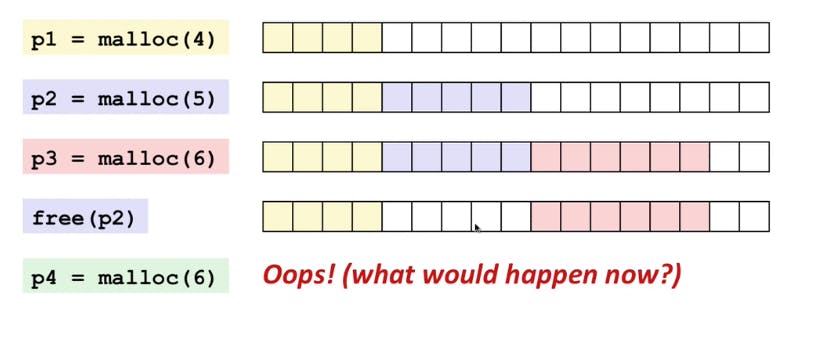
At p4 step even though we have enough memory block we cannot fulfil the request for 6 contiguous blocks of memory resulting in memory fragmentation. Some languages use smart algorithms for allocating memory. Instead of allocating memory for a lot of small objects, they pre-allocate memory for a contiguous array of those smaller objects. Other language add a compacting step to their GC process.
Compacting
Compacting simply moves all live objects to one end of the heap, which effectively closes all holes. Objects can be allocated at full speed (no free lists are needed anymore), and problems creating large objects are avoided. Moving these objects will take some time, resulting on an even longer GC process.
Escape Analysis
Escape Analysis (EA) is a very important technique that some languages can use to analyse the scope of a new object and decide whether it might not be allocated to heap space. So, instead of creating every single object on the heap, some of them can be kept on the method stack. This is a very important performance optimisation because stack allocation and de-allocation are much faster than heap space allocation.
Ownership
Any value must have a variable as its owner(and only one owner at a time) when the owner goes out of scope the value will be dropped freeing the memory regardless of it being in stack or heap memory.
Summary
In this part we learned about the most important concepts that we will need to know before diving into the implementation details of different programming languages. In the next parts I will use all these concepts to explain how are they connected and how each programming language utilise some of them to implement it's memory management strategies.
Resources
- freecodecamp.org/news/garbage-collection-in..
- youtube.com/watch?v=UnaNQgzw4zY
- jarombek.com/blog/nov-10-2019-garbage-colle..
- stackify.com/python-garbage-collection
- stackoverflow.com/questions/79923/what-and-..
- medium.com/clearscore/what-is-arc-and-how-d..
- medium.com/@ankur_anand/a-visual-guide-to-g..
- deepu.tech/memory-management-in-programming